KNIME 実践編 / 解約予測
KNIME 実践編 / 解約予測
- 初版作成日: 2020-05-07
- 最終更新日: 2020-05-15
今回は、実践編の第一回目として、 Kaggle / Telecom Customer Churn Prediction (電話会社 顧客 解約予測) のデータを使って複数の予測モデルを実装し、精度を比較します。
データの前処理から始まり、その後複数のモデル作成とモデル評価を行います。最後に4つのモデルの精度を比較します。次の4モデルを利用し解約予測を実装します。
- Decision Tree (決定木)
- Logistic Regression (ロジスティック回帰)
- Random Forest (ランダムフォレスト)
- Multi Layer Perceptron (多層パーセプトロン)
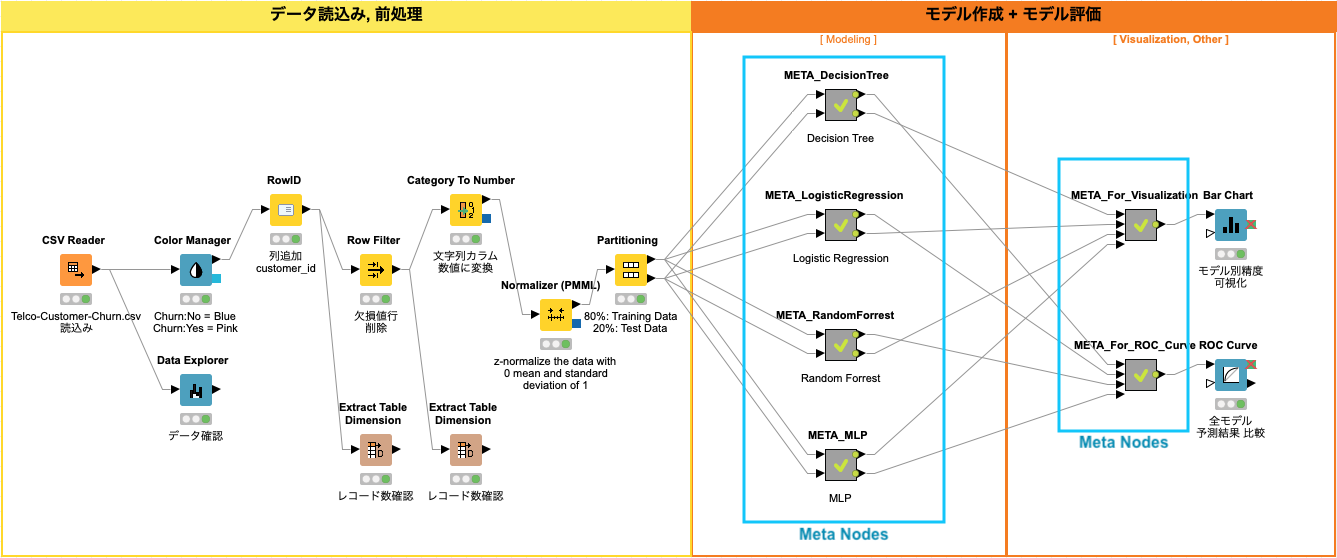
ワークフロー全体
KNIMEで実装するワークフローを二つのパートに分けて管理しています。
- データ読み込み + 前処理
- モデル作成 + モデル評価
KNIMEの最大の長所は、ワークフローを見ただけで全体の処理の流れの俯瞰することができることです。また、各モデルの実装 (Modeling) を メタノード にすることで、メインのワークフローをより理解し易くすることが可能です。
Fig. 全体ワークフロー
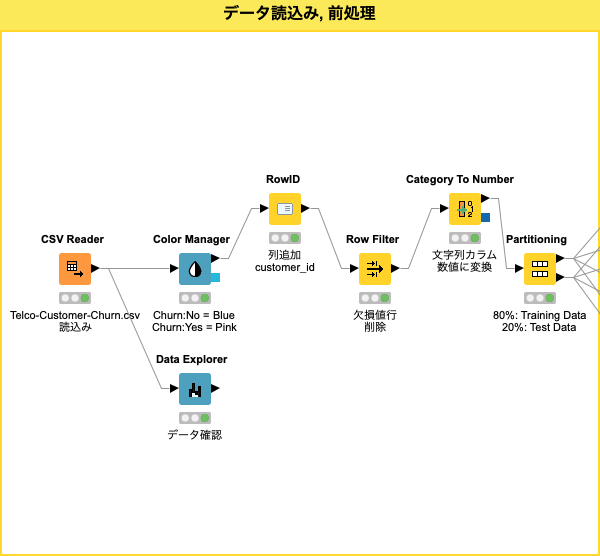
分析用データ読み込み, 前処理
このワークフロー パートでは、Kaggle / Telecom Customer Churn Prediction (電話会社 顧客 解約予測) からダウンロードしたデータをKNIMEにロードし、その後前処理を実行します。
前処理では、データ確認後、判別クラス カラムの色設定、いくつかのデータ処理を経た後に、サンプル (データ) をトレーニングデータとテストデータに分割します。
Fig. 分析用データ読み込み, 前処理 ワークフロー
分析用データ読み込み
Kaggle / Telecom Customer Churn Prediction (電話会社 顧客 解約予測) からダウンロードしたデータをKNIMEにロードします。CSV Readerノード の設定で 特に気をつける箇所は、 以下の3点です。
- CSVファイルの文字コードが UTF-8 であること
- 行見出しの存在有無 (Has Row Header)
- デリミター文字 (Column Delimiter)
Fig. 分析用データ読み込み/設定
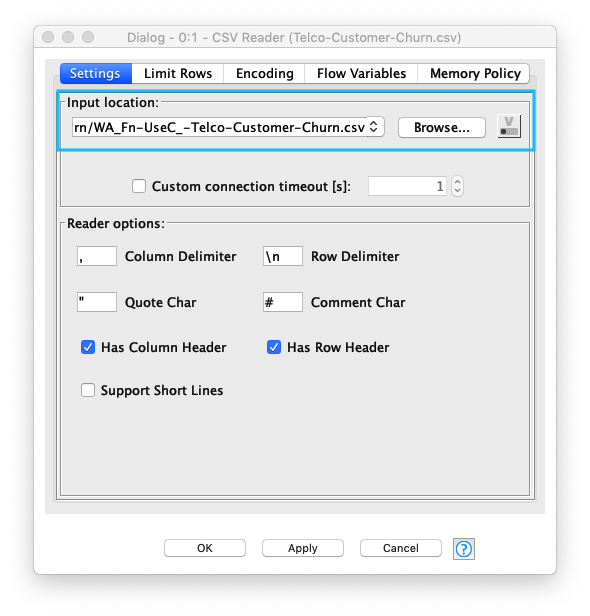
- 利用ノード: IO / Read / CSV Reader
データ確認
Data Explorerノードを利用して、サンプルの各カラムの分布を確認します。Numericタブ で数値カラムの統計情報とチャート が出力されます。(Fig. データ確認 (1), Fig. データ確認 (2))
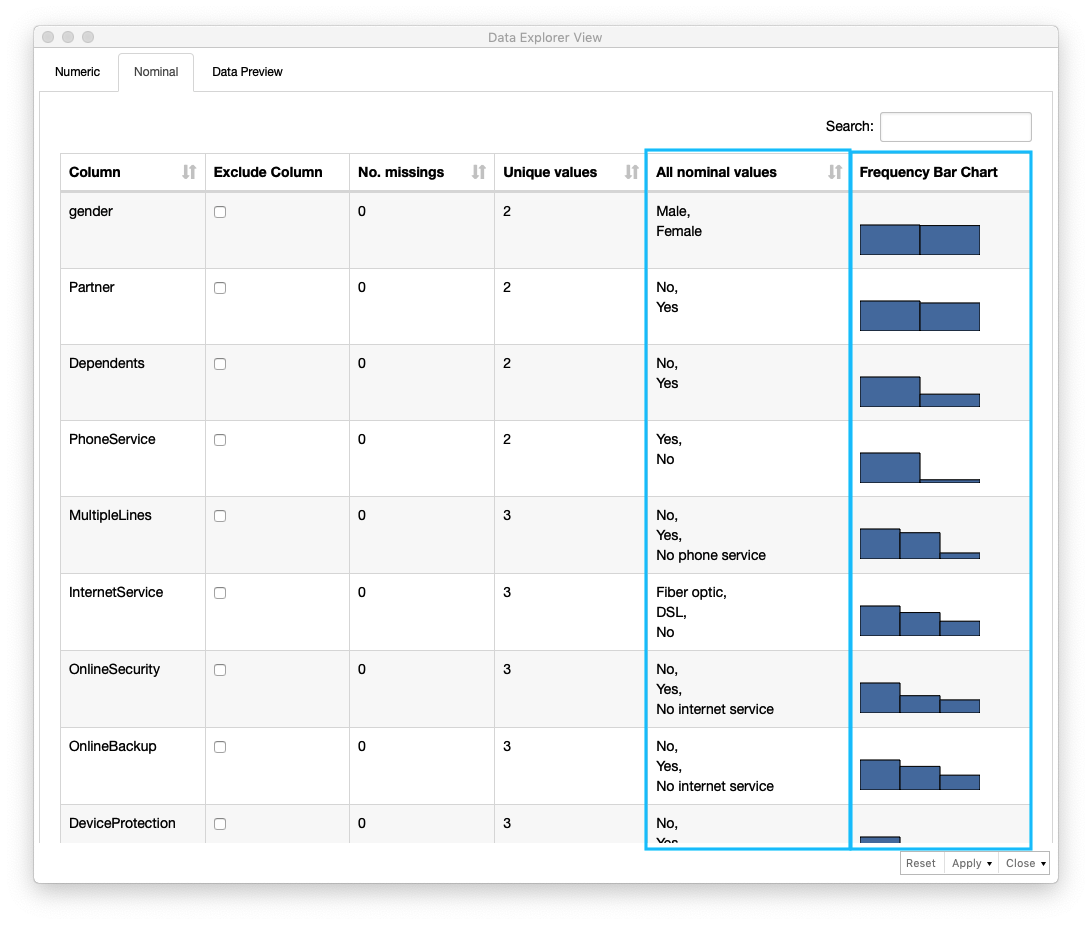
一方、数値以外のカラムに関しては、Nominalタブ に各カラムの情報が出力されます。これらの情報からサンプルの特徴を把握します。(Fig. データ確認 (3))
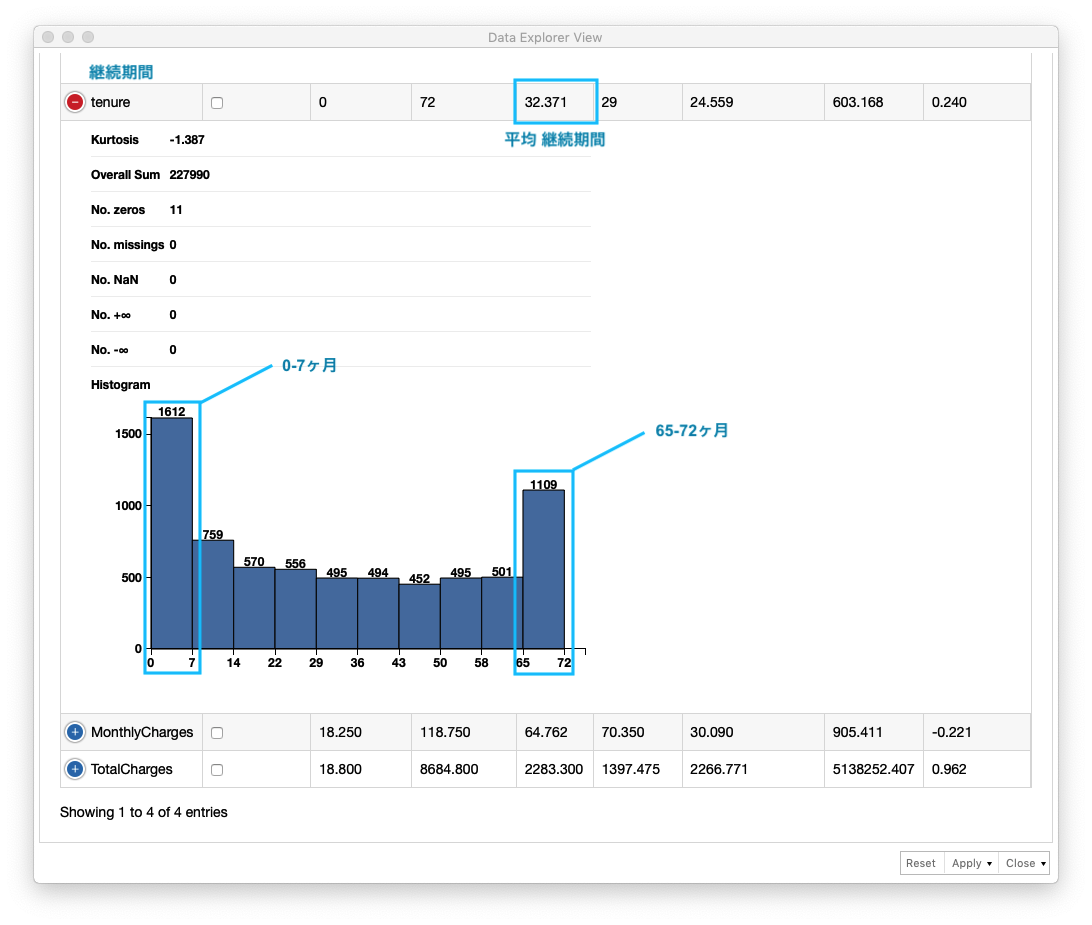
Fig. データ確認 (1)
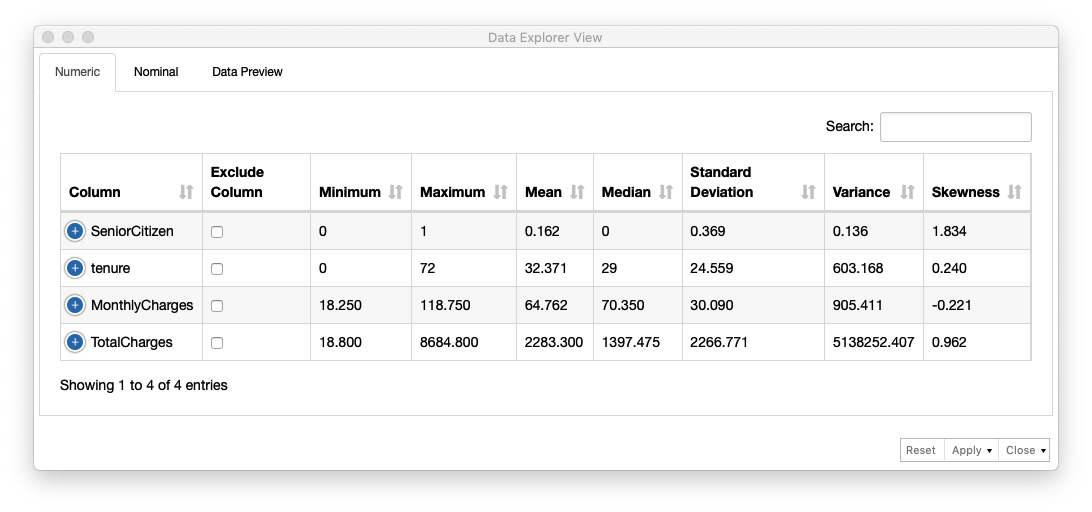
tenure (継続期間) の分布を確認します。平均 継続期間が 32.371ヶ月、0-7ヶ月の範囲に会員数が最も多く、次に多いのが 65-72ヶ月であることがわかります。0-7ヶ月以後、 会員の約半数が解約していることがわかります。以上から tenure (継続期間) が 解約/継続を判別する重要なデータであると言えます。
Fig. データ確認 (2)
数値以外のカラムのデータは、Nominalタブ内に出力される各カラムの情報 - 欠損値数 (No. missings)、ユニークな値の数、値のリスト、データの分布 を確認します。
Fig. データ確認 (3)
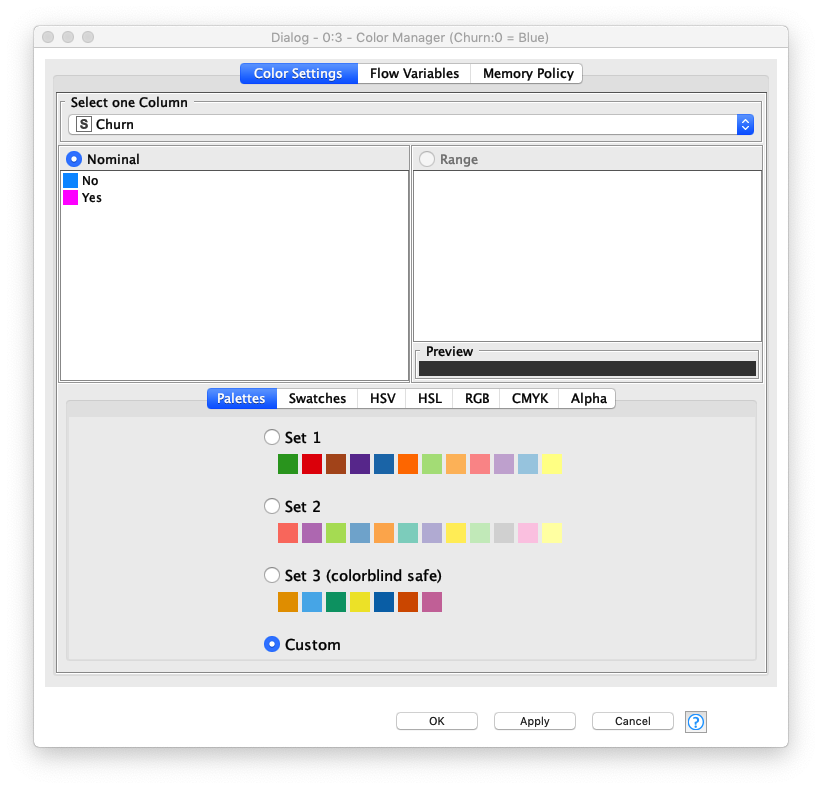
色識別設定
判別対象のカラムの値を識別し易くする為、Color Managerノード を利用します。Churnカラムの値、No と Yes に色を指定します。
Fig. 継続/解約 色設定
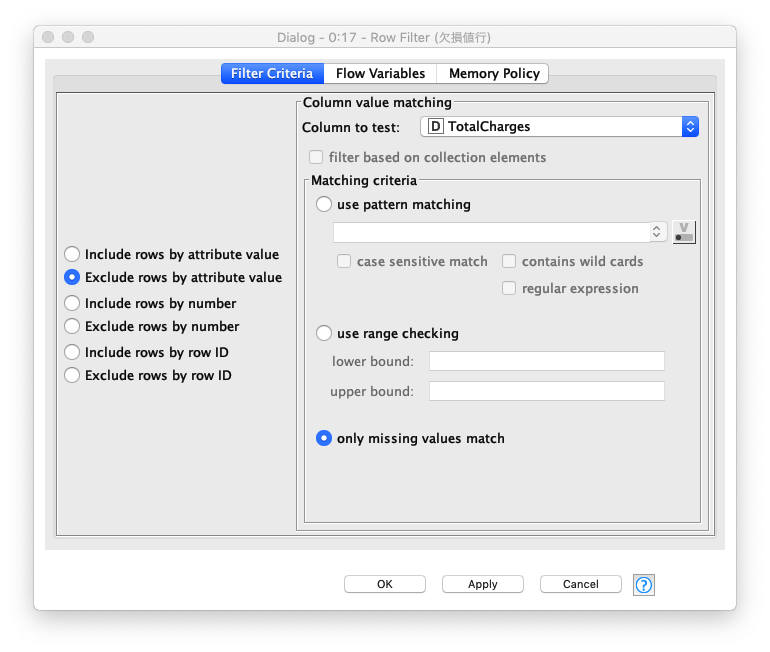
欠損値含む行削除
欠損値数が少ない為 (総行数:7043件, 欠損値行数11件)、この演習では欠損値を含むデータを削除します。
Fig. 欠損値 設定
文字列カラムの数値変換
モデル構築時に扱うデータは数値型が要求される為、文字列を値にもつカラムのデータを数値型に変換します。対象とするカラムは、次の4カラムです。
- InternetService
- OnlineSecurity
- TechSupport
- Contract
Fig. 文字列カラム 数値変換 / 設定
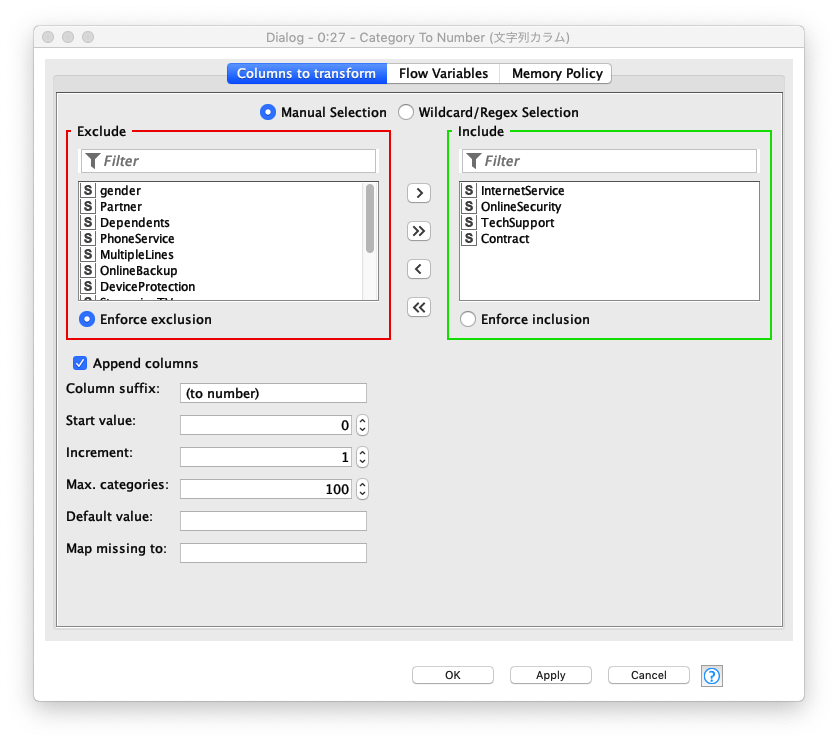
テーブル分割
Fig. テーブル分割 / 設定
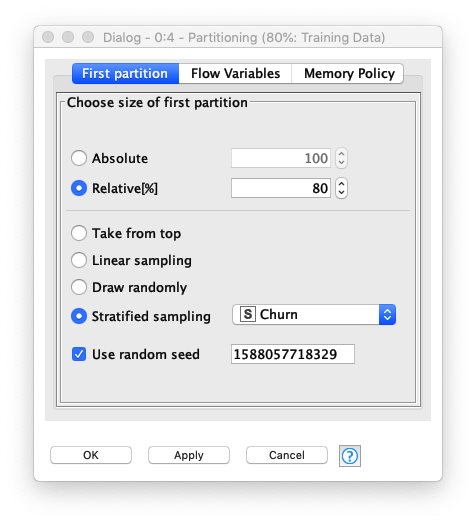
入力テーブルは2つのパーティション (トレーニング用とテスト用) に分割されます。 それぞれのパーティションには、出力ポートが存在するので、このノードの後ろに繋がるノードは、分割されたテーブルを利用することになります。今回の演習では、**トレーニング用レコード と テスト用レコードの割合を 「80% : 20%」に設定**しています。
モデリング
Fig. モデル作成, モデル評価 ワークフロー
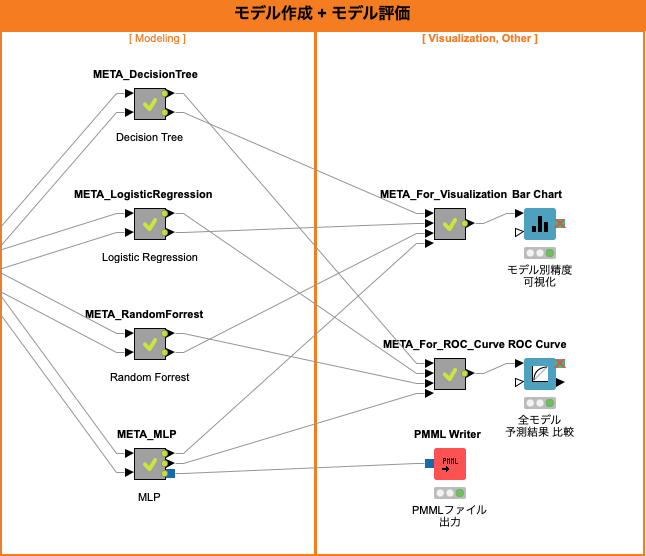
Decision Tree (決定木)
Decision Tree (決定木) は、回帰分析、クラス分類に利用されます。回帰モデル、クラス分類モデルが Tree(木)構造のため、モデルを直感的に理解することができます。その反面、このモデルの精度は他の高度なモデルよりも精度が落ちる事が多いと言われています。
Fig. Decision Tree ワークフロー
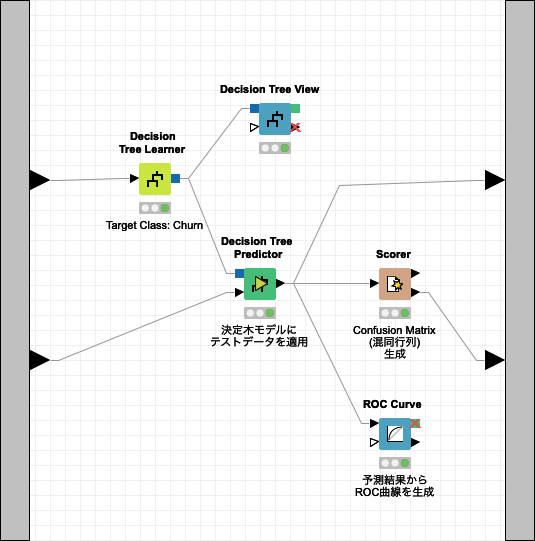
学習
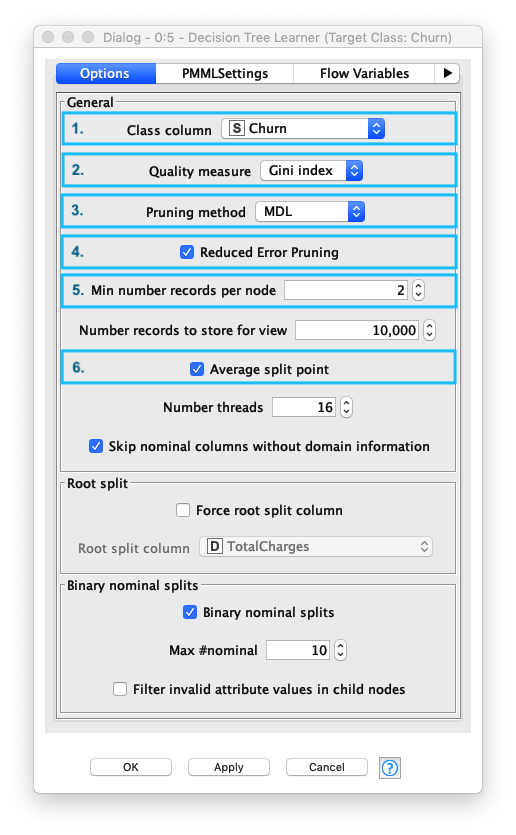
Decision Tree Learningノードの設定画面で、以下の6つの項目を設定します。データの特徴、分析内容に従って これらの設定を行う必要があります。
| 項目 | 説明 | 設定 |
|---|---|---|
| 1. Class column | 分類対象クラスのカラム名 | Churn (解約/継続カラム) |
| 2. Quality measure | データ分割手法: - Gini Index- Gain Ratio |
Gini Index 1 |
| 3. Pruning method | 剪定有無: - MDL (最小記述長) - 過学習抑止- No pruning (無剪定) |
MDL 2 |
| 4. Reduced Error Pruning | 単純な剪定方法を使用、剪定エラーの削減には単純さと速度の利点がある | ON |
| 5. Min number records per node | 各ノードで最低限必要なレコードの最小数を指定する レコード数がこの指定値以下の場合、ツリーはそれ以上大きくならない |
2 |
| 6. Average split point | - ON: 数値属性の分割値は、2つのパーティションを分離する2つの属性値の平均値に従って決定される - OFF: 分割値は下位パーティションの最大値に設定される |
ON |
Fig. Decision Tree / 学習.設定
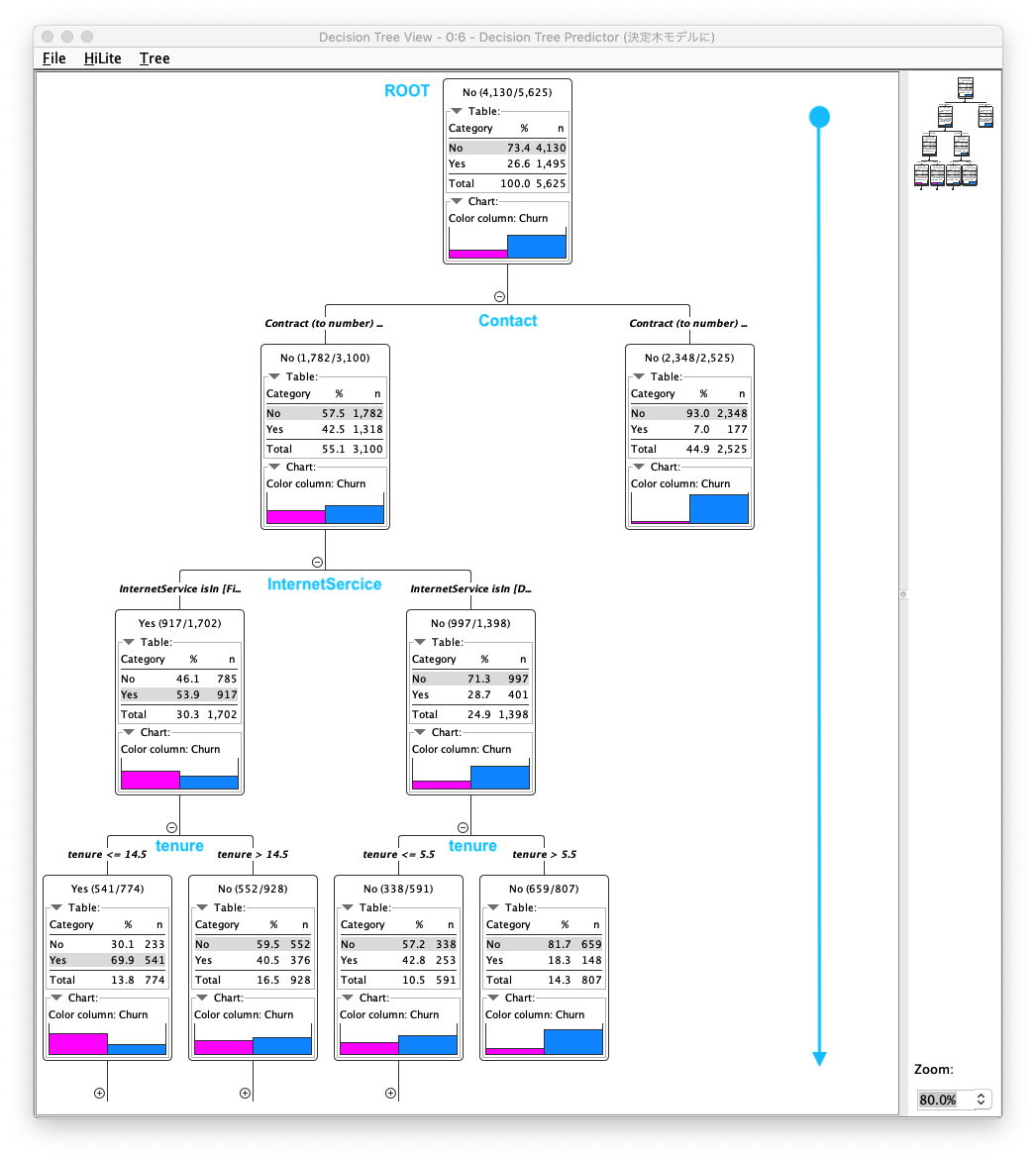
Decision Tree Learnerノードの実行結果を確認することで、生成された Decision Tree(決定木) を確認できます。Decision Treeは、二分木構造であり、根から葉に向かって順番に条件分岐を辿ることで最終的な結果を返すことがわかります。図を見ると、ROOT 〜 Contract 〜 InternetService 〜 tenure ... - Decision Tree (決定木) が構築されていることがわかります。
Fig. Decision Tree / 学習.結果
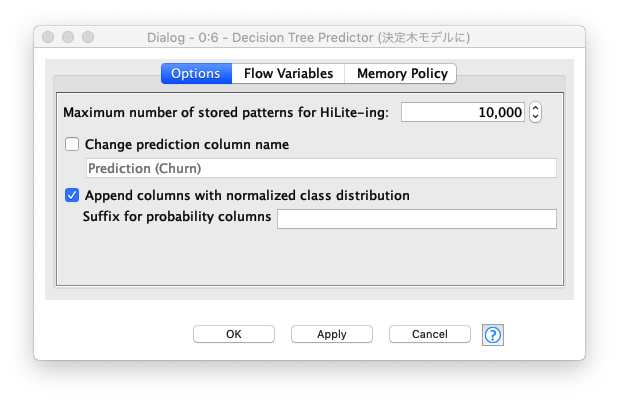
予測
Decision Tree Predictorノードの設定は、Append columns with normalized class distribution (正規化されたクラス分布で列を追加する) を "ON" にすることで、各予測の正規化されたクラス分布を表示します。
Fig. Decision Tree / 予測.設定
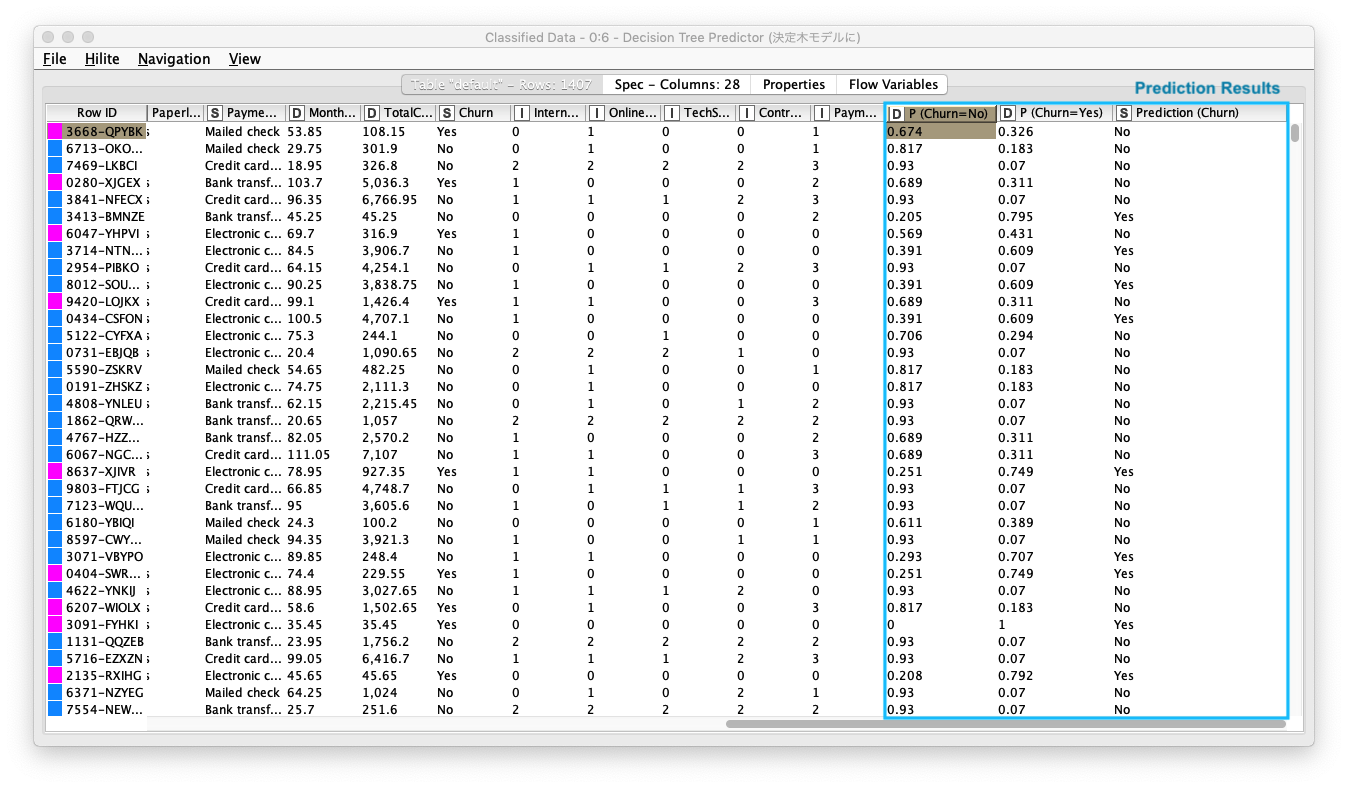
既存のテーブルに 以下の3カラムが追加されていることを確認します。次のステップでは、継続/退会 の判別精度を評価します。
- P (Churn = No) :
Churn = Noの割合 - P (Churn = Yes) :
Churn = Yesの割合 - Prediction (Churn) : 予測結果
Fig. Decision Tree / 予測.結果
評価(1)
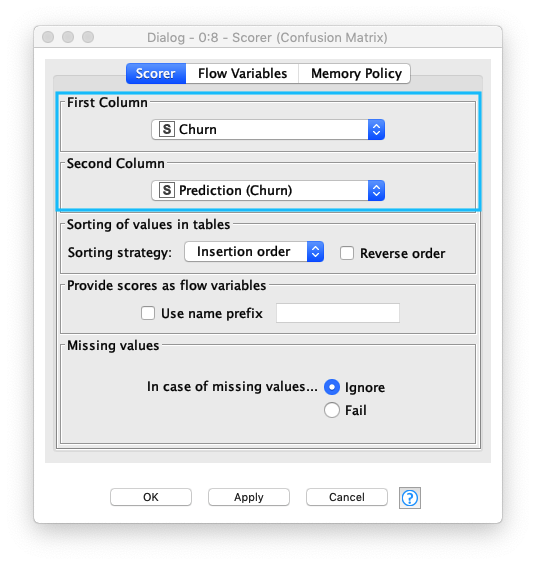
継続/退会 の判別精度を評価するため、次の通り Sorerノード を設定します。
- First Column (データの実クラス) :
Churn - Second Column (データの予測クラス) :
Prediction (Churn)
Fig. Decision Tree / 評価(1).設定
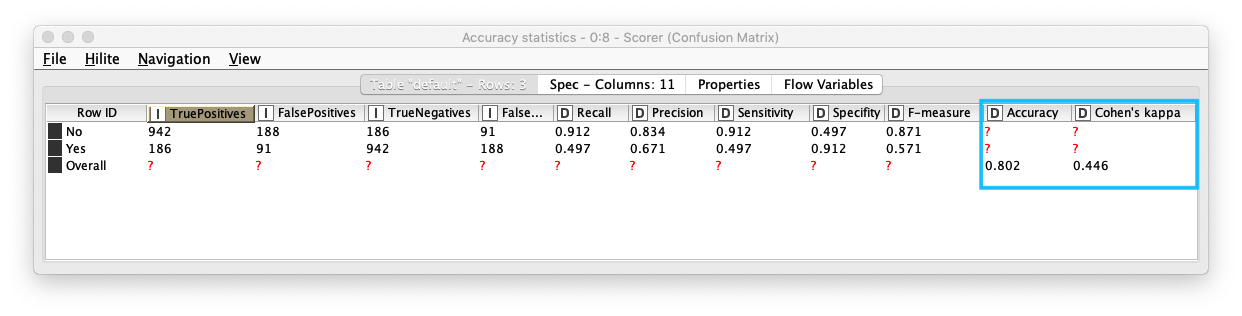
Scorerノードを実行すると Confusion Matix (混同行列) をテーブル形式で表示します。また、Accuracy Statistics (下図参照) (精度統計) を表示することで、詳細な精度を確認することができます。
- Accuracy (精度) : 0.802
- Kohen's Kappa (カッパ係数) 3 : 0.446 - 中等度の一致 (moderate agreement)
Fig. Decision Tree / 評価(1).結果
Accuracy (精度), Kohen's Kappa (カッパ係数) 共に 1.0に近づくほど精度が高いとされています。カッパ係数の基準 - Landis and Koch 基準があります。
Landis and Koch 基準
| カッパ係数 範囲 | 解釈 |
|---|---|
| 0.00 - 0.20 | わずかに一致 (slight agreement) |
| 0.21 - 0.40 | まずまずの一致 (fair agreement) |
| 0.41 - 0.60 | 中等度の一致 (moderate agreement) |
| 0.61 - 0.80 | かなりの一致 (substantial agreement) |
| 0.81 - 1.00 | ほぼ完全、完全一致 (almost perfect or perfect agreement) |
評価(2)
ROC (Receiver Operating Characteristic) Curve (ROC曲線) は、二値分類の評価で使われます。Y軸にTPR (True Positive Rate - 真陽性率)、X軸に FPR (False Positive Rate - 偽陽性立) の割合をプロットします。AUC (Area Under the Curve) は、その曲線の下部の面のことであり、AUC の面積が大きいほどモデルの性能が良いとされています。
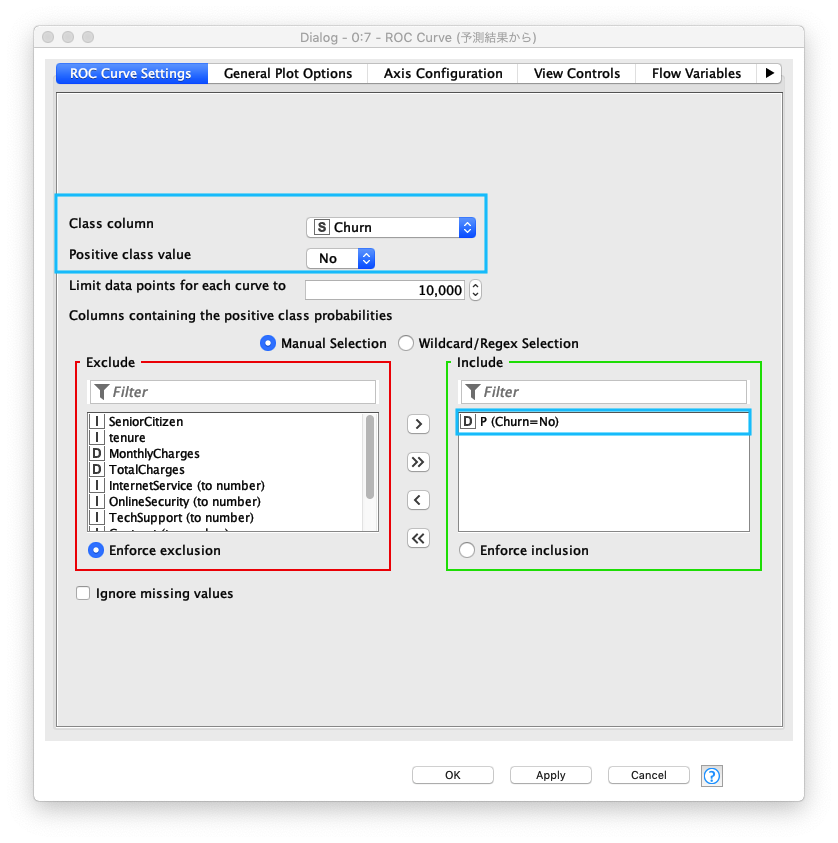
以下の通り ROC Curveノード を設定します
- Class column : Churn
- Positive class value : No
- Columns containing the positive class probablities : P (Chuen = No)
Fig. Decision Tree / 評価(2).設定
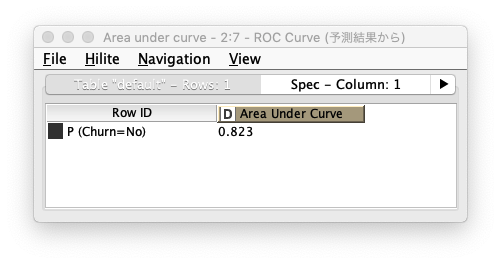
ROC Curveノード の実行結果は、次の通り 「AUC: 0.823」 であることがわかります
Fig. Decision Tree / 評価(2).結果 - ROC曲線
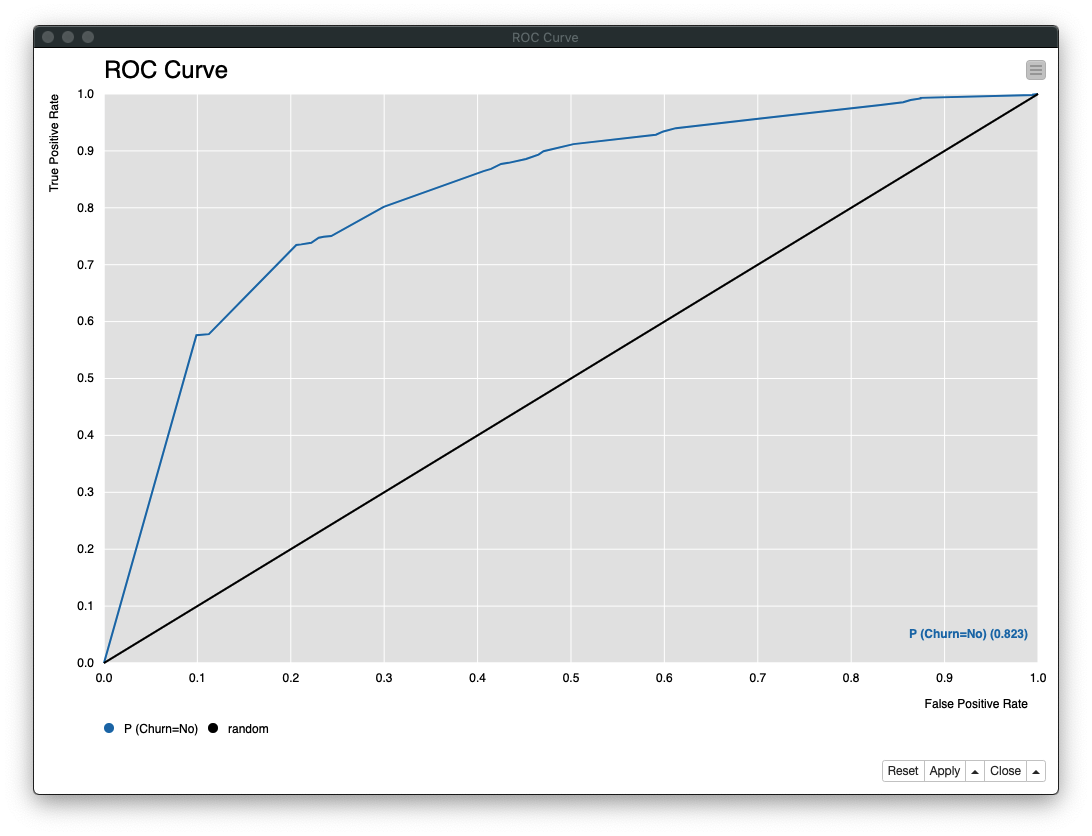
Fig. Decision Tree / 評価(2).結果 - AUC
利用ノード
- Nodes / Analytics / Mining / Decision Tree / Decision Tree Learner
- Nodes / Analytics / Mining / Decision Tree / Decision Tree Predictor
- Nodes / Views / JavaScript / Decision Tree View
- Nodes / Analytics / Mining / Scoring / Scorer
- Nodes / Views / JavaScript / ROC Curve
Logistic Regression (ロジスティック回帰)
ロジスティック回帰は、線形分類器の一種であり、教師あり学習の分類タスクに利用されるアルゴリズムです。ある事象が発生する確率を学習し、与えられたデータを2値分類 (目的変数が2値, 3値分類以上も可能) します。
シグモイド関数の数式は次のとおりです。シグモイド関数 hθ(x) の取りうる値域は 0 < hθ(x) < 1 の為、分類の成立確率を算出するロジスティック回帰と相性が良いとされています。
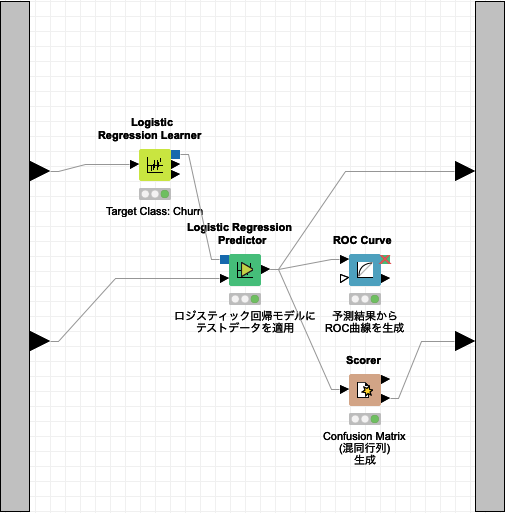
Logistic Regressionワークフローは、Learner (学習器)、Predictor (予測子)、Scorer (評価: スコアラー), ROC Curve (評価: ROC曲線) の4つのノードから成り立ちます。
Fig. Logistic Regression ワークフロー
学習
Logistic Regression Learnerノードの 1. Target column (ターゲット列)、2. Reference category (参照カテゴリ)、3. Feature selection (説明変数の設定) を設定します。
- Target Column (ターゲット列) には、Decision Tree (決定木)と同じ
Churnを指定する - Reference category (参照カテゴリ) には、
No (継続) - Use column attributes (説明変数の設定)も Decision Tree (決定木)と同様のカラムを複数指定する
Fig. Logistic Regression Learner 設定
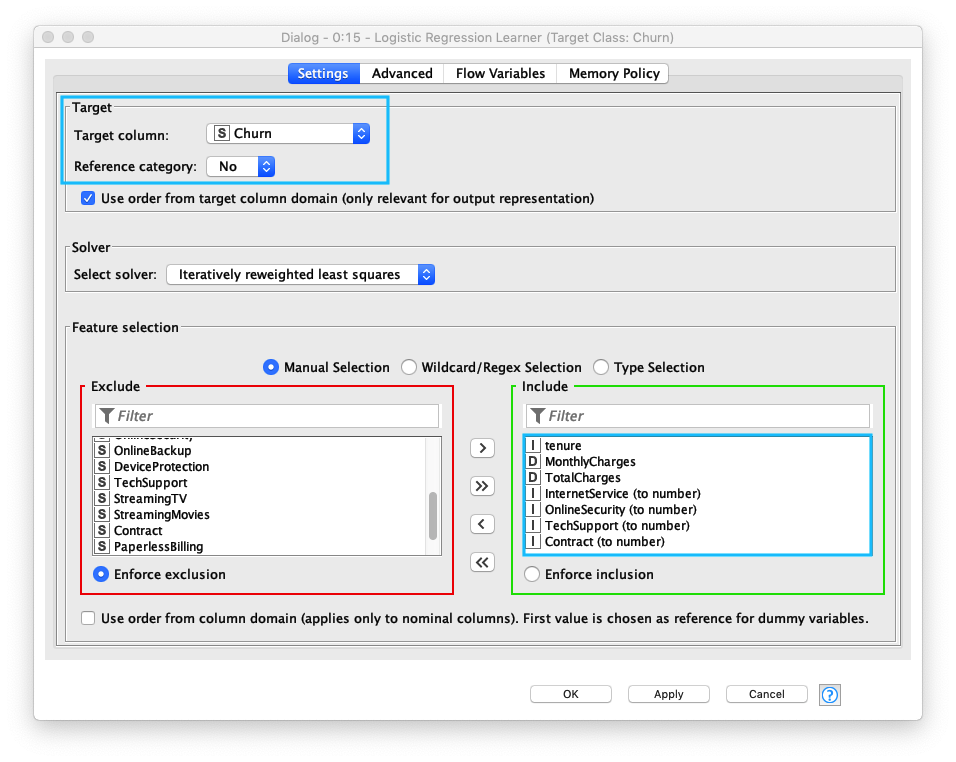
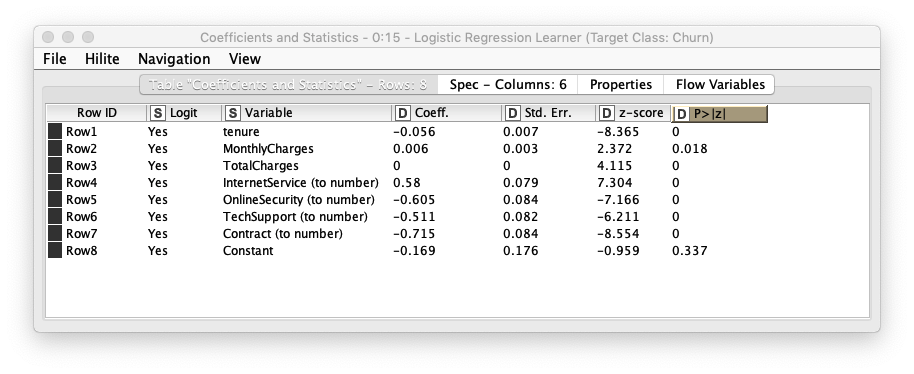
Fig. Logistic Regression Learner 実行結果
予測
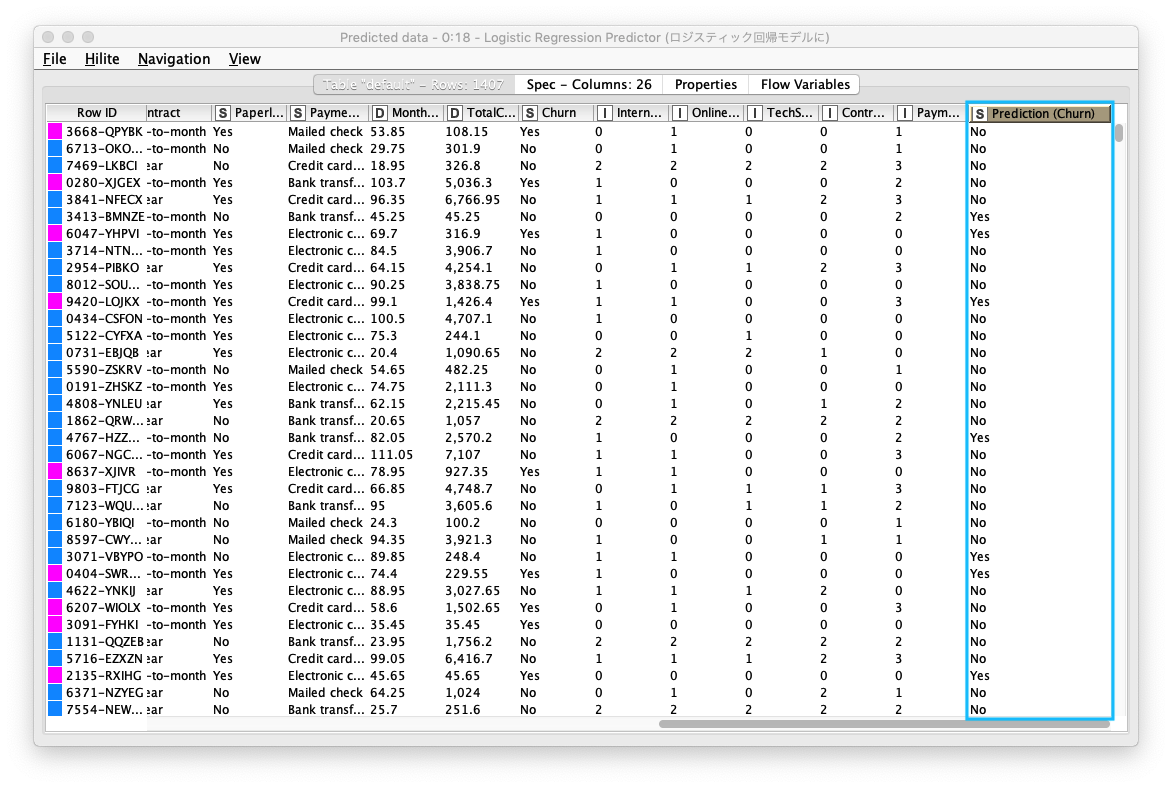
Logistic Regression Predictorノードの設定は、デフォルトのままで変更せずに実行します。実行結果のテーブルには、Prediction (Churn) が追加されます。次のステップでは、継続/退会 の判別精度を評価します。
Fig. Logistic Regression Predictor 設定
Fig. Logistic Regression Predictor 実行結果
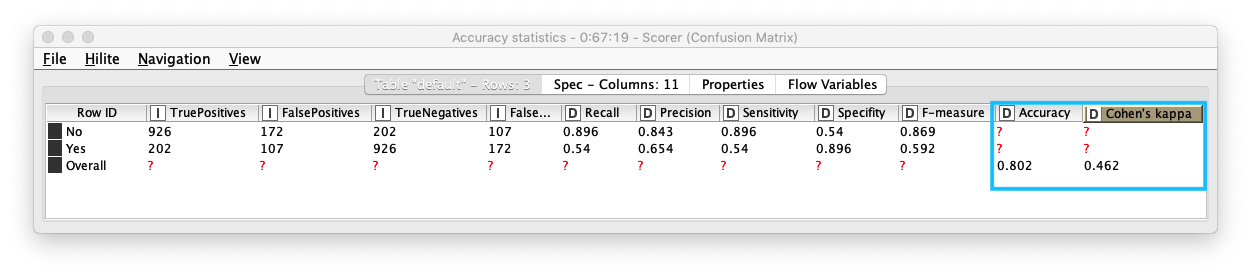
評価 (1)
Scorerノードを実行すると Confusion Matix (混同行列) をテーブル形式で表示します。また、Accuracy Statistics (下図参照) (精度統計) を表示することで、詳細な精度を確認することができます。
- Accuracy (精度) : 0.802
- Kohen's Kappa (カッパ係数) 3 : 0.462 - 中等度の一致 (moderate agreement)
Fig. Scorer / Cofusion Matrix (混同行列)
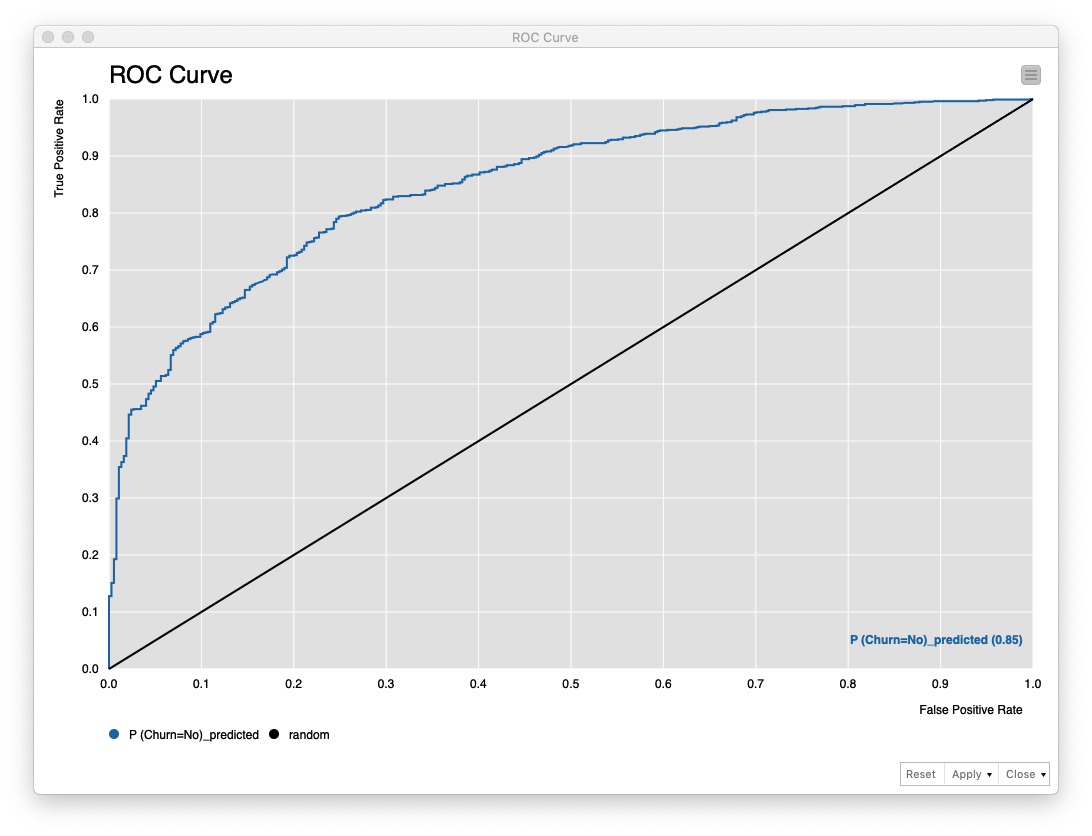
評価 (2)
ROC Curveノード の実行結果は、次の通り 「AUC: 0.85」 であることがわかります。
Fig. ROC Curve (ROC曲線)
利用ノード
- Nodes / Analytics / Mining / Logistic Regression / Logistic Regression Learner
- Nodes / Analytics / Mining / Logistic Regression / Logistic Regression Predictor
Random Forest (ランダムフォレスト)
Random Forest (ランダムフォレスト)は、モデルリング章の一番最初に紹介した Decision Tree (決定木) を複数利用することで、それ単体よりも予測精度を向上させるアルゴリズムです。複数のDecision Tree (決定木) から得られた予測結果を多数決し妥当な結果を得ます。また、このモデルは、分類と回帰に利用することができます。
Fig. Random Forest ワークフロー
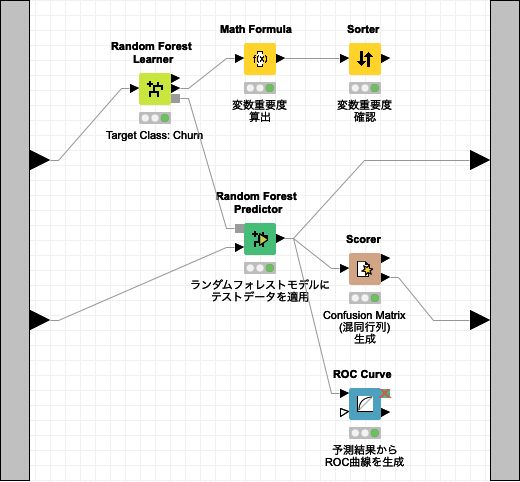
学習
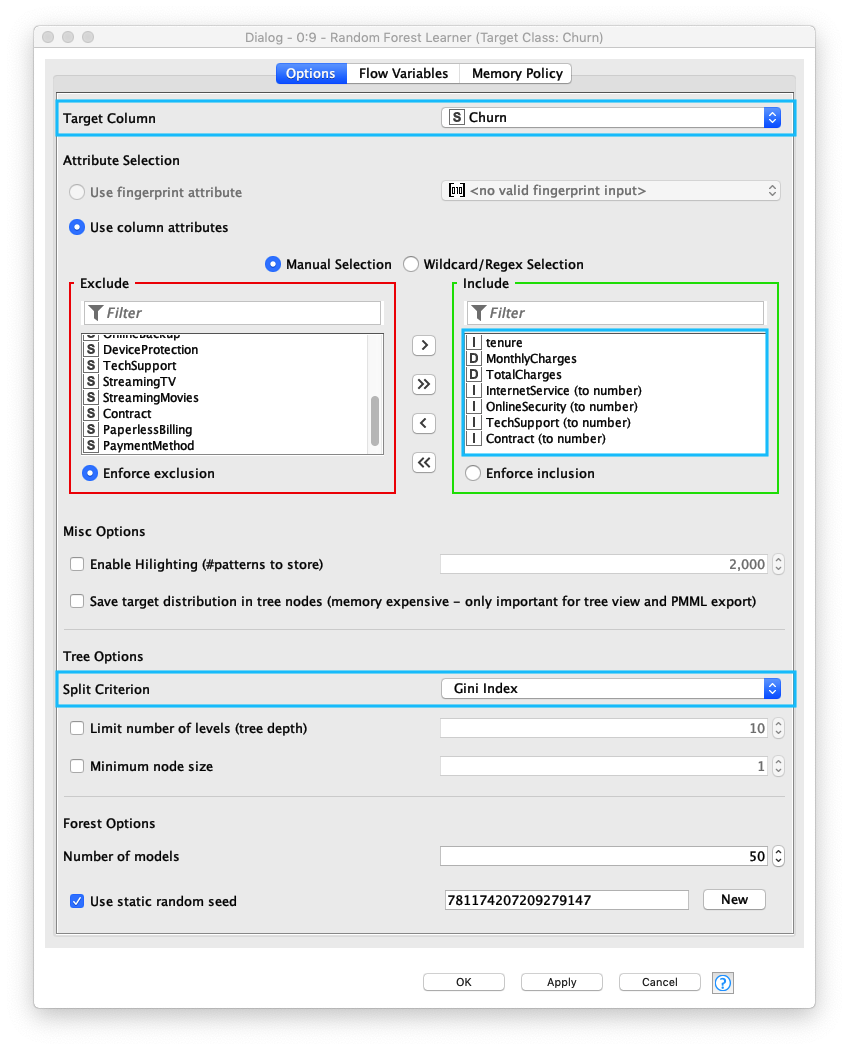
Randome Forest Learnerノードの 1. Target Column (ターゲット列)、2. Use column attributes (説明変数の設定)、3. Split Criterion (分割基準) を設定します。
- Target Column (ターゲット列)には、Decision Tree (決定木)と同じ
Churnを指定する - Use column attributes (説明変数の設定)も 同様のカラムを複数指定する
- Split Criterion (分割基準)は、一般的に Gini Index (Gini係数) を指定することが多いので、それを指定する
Fig. Randome Forest Learner 設定
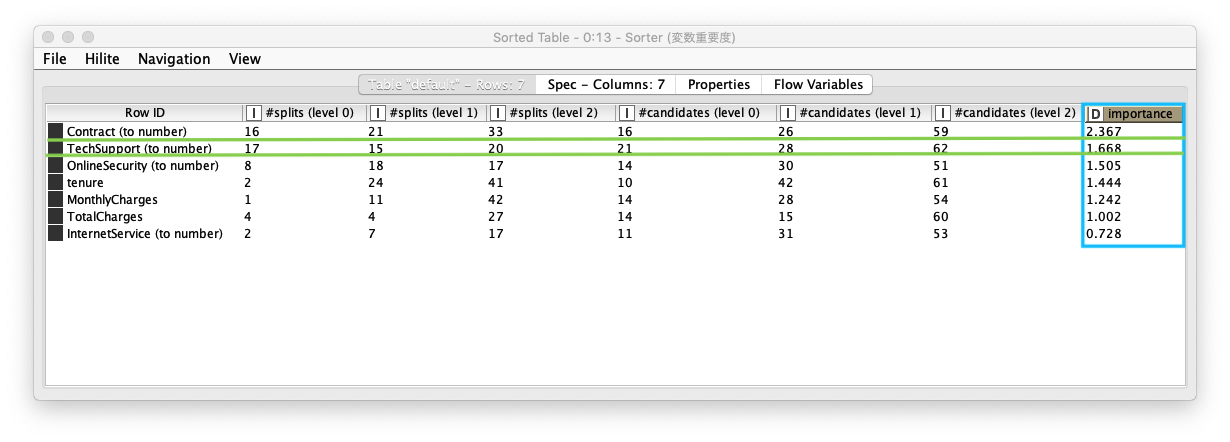
説明変数の重要度評価を行い、どの説明変数が判別に貢献しているのか確認します。Importance (重要度) カラム の降順 (Ascending Order) でソートした結果、1. Contract (契約)、2. TechSupport (テクニカルサポート) の順で良いことがわかります。
Fig. 説明変数 重要度評価 結果 (Sorterノード)
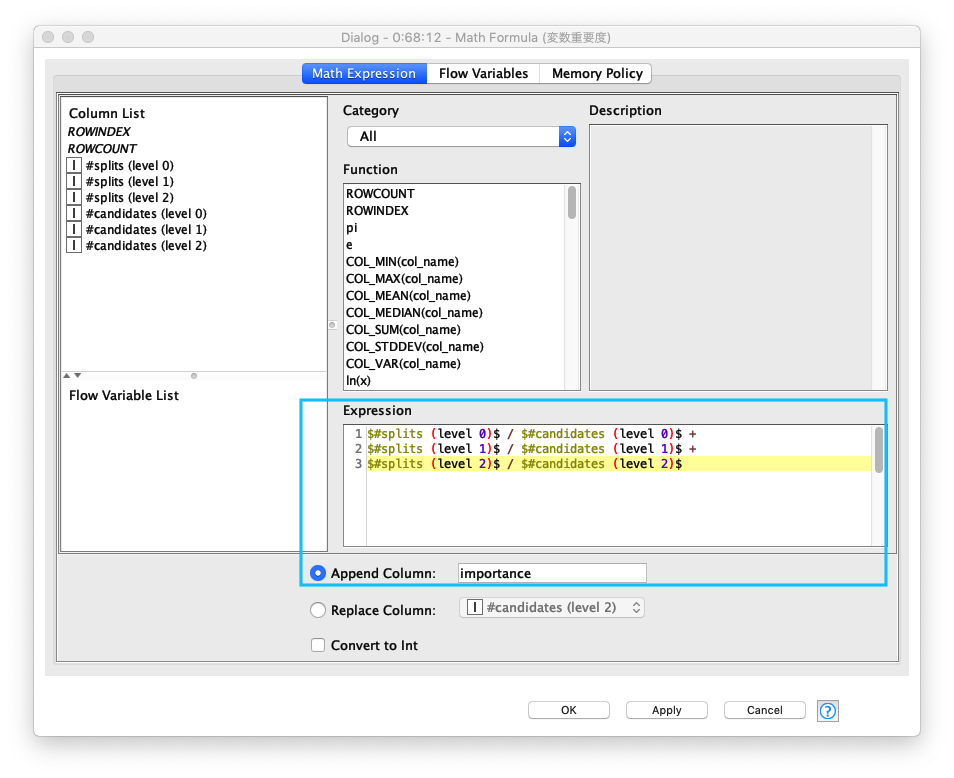
Importance (重要度) を算出する計算式は次の通りです。
1 2 3 | |
Fig. 説明変数 重要度評価 計算式 (Math Formulaノード)
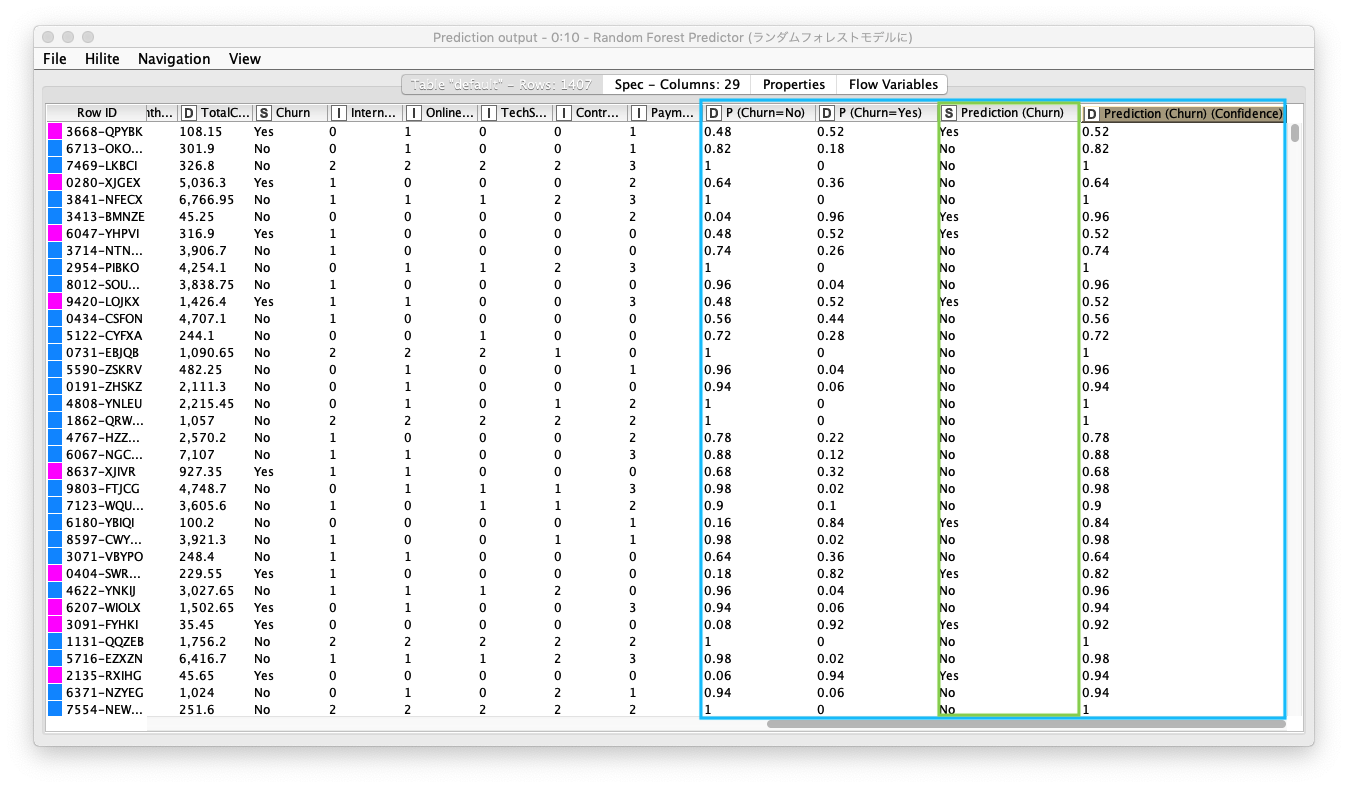
予測
既存のテーブルに 以下の4カラムが追加されていることを確認します。次のステップでは、継続/退会 の判別精度を評価します。
- P (Churn = No) :
Churn = Noの割合 - P (Churn = Yes) :
Churn = Yesの割合 - Prediction (Churn) : 予測結果
- Prediction (Churn) (Confidence): 予測結果の信頼係数
Fig. Randome Forest Predictor 実行結果
評価 (1)
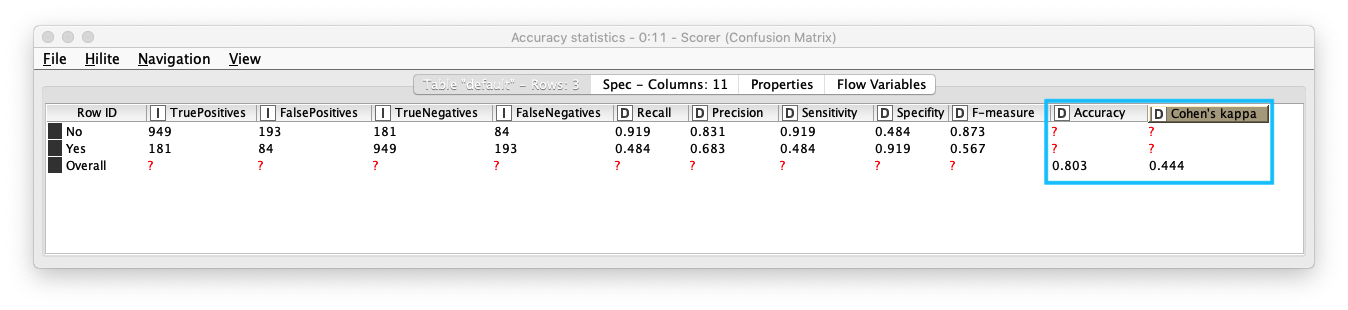
Scorerノードを実行すると Confusion Matix (混同行列) をテーブル形式で表示します。また、Accuracy Statistics (下図参照) (精度統計) を表示することで、詳細な精度を確認することができます。
- Accuracy (精度) : 0.803
- Kohen's Kappa (カッパ係数) 3 : 0.444 - 中等度の一致 (moderate agreement)
Fig. Scorer / Cofusion Matrix (混同行列)
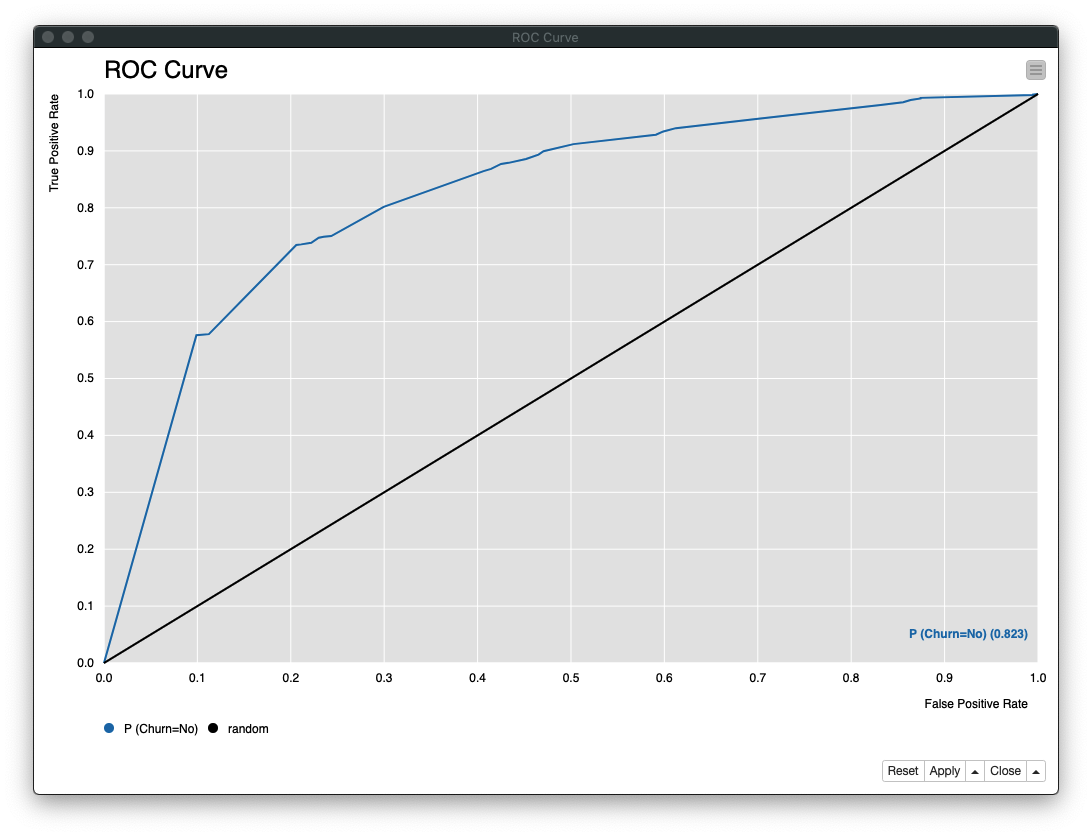
評価 (2)
ROC Curveノード の実行結果は、次の通り 「AUC: 0.823」 であることがわかります。
Fig. ROC Curve (ROC曲線)
利用ノード
- Nodes / Analytics / Mining / Decision Tree Ensemble / Random Forest / Classification / Random Forest Learner
- Nodes / Analytics / Mining / Decision Tree Ensemble / Random Forest / Classification / Random Forest Predictor
- Nodes / Manipulation / Column / Convert & Replace / Math Formula
- Nodes / Manipulation / Row / Transform / Sorter
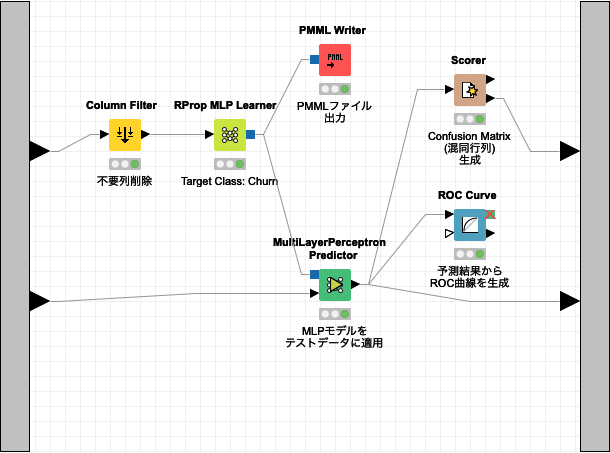
Multi Layer Perceptron (多層パセプトロン)
Multi Layer Perceptron (多層パセプトロン) は、順伝播型ニューラルネットワークに属するアルゴリズムです。それは、単純パーセプトロンを複数繋いで多層構造 (入力層、隠れ層/中間層、出力層) にしたニューラルネットワークです。多層構造 (ユニット数、階層) は、作成するモデルによって決定します。
Fig. Multi Layer Perceptron ワークフロー
学習
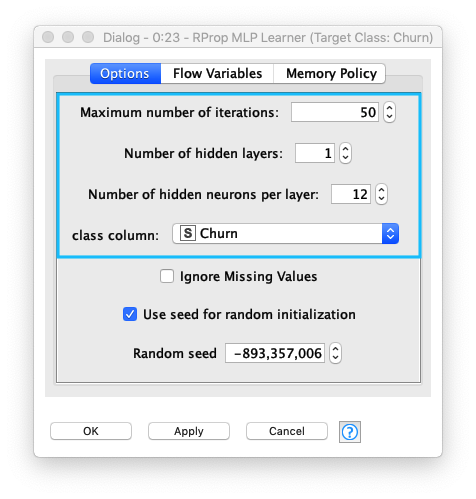
Multi Layer Perceptron Learner ノードの 1. Maximum number of iteratioins (最大イテレーション数) 、2. Number of hidden layers (隠れ層数/中間層数)、3. Number of hidden neurons per layer (隠れニューロン数/層)、4. Class column (クラスカラム名) を設定します。
- Maximum number of iteratioins (最大イテレーション数) : 50
- Number of hidden layers (隠れ層数/中間層数) : 1
- Number of hidden neurons per layer (隠れニューロン数/層) : 12
- Class column (クラスカラム名) :
Churn- 判別対象カラム
Fig. Multi Layer Perceptron Learner 設定
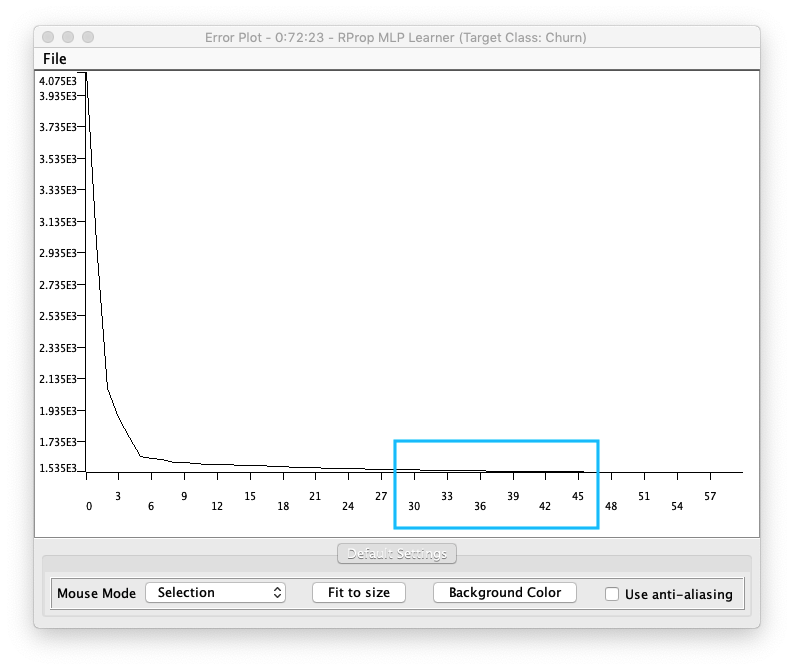
学習実行後、各イテレーションのエラー数を表示します。チャートを見ると **38 - 40回でエラーが収束**していることがわかります。
Fig. Multi Layer Perceptron Learner 学習結果
予測
既存のテーブルに 以下の3カラムが追加されていることを確認します。次のステップでは、継続/退会 の判別精度を評価します。
- P (Churn = No) :
Churn = Noの割合 - P (Churn = Yes) :
Churn = Yesの割合 - Prediction (Churn) : 予測結果
Fig. Multi Layer Perceptron Learner 予測結果
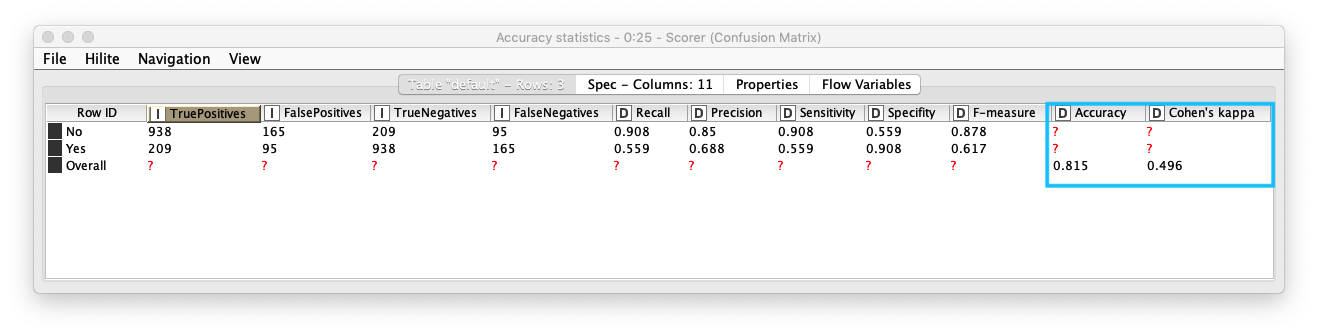
評価 (1)
Scorerノードを実行すると Confusion Matix (混同行列) をテーブル形式で表示します。また、Accuracy Statistics (下図参照) (精度統計) を表示することで、詳細な精度を確認することができます。
- Accuracy (精度) : 0.815
- Kohen's Kappa (カッパ係数) 3 : 0.496 - 中等度の一致 (moderate agreement)
Fig. Scorer / Cofusion Matrix (混同行列)
評価 (2)
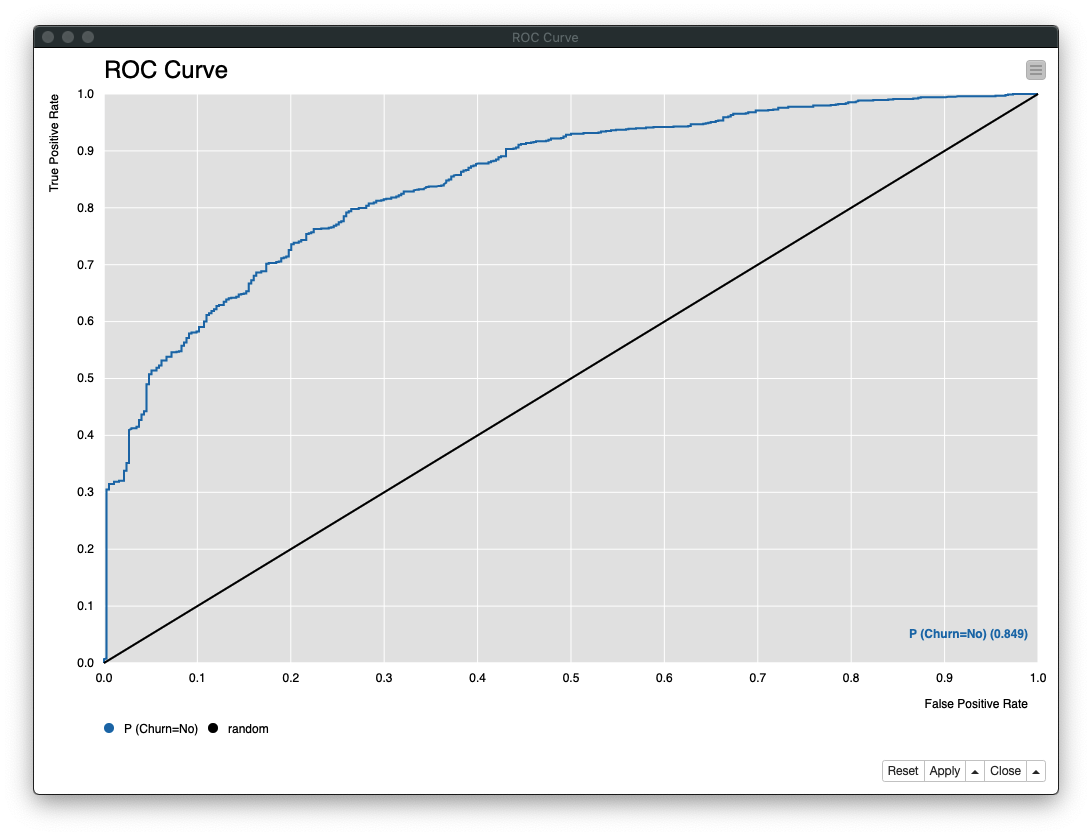
ROC Curveノード の実行結果は、次の通り 「AUC: 0.849」 であることがわかります。
Fig. ROC Curve (ROC曲線)
利用ノード
- Nodes / Manipulation / Column / Filter
- Nodes / Analytics / Mining / Neural Network / MLP / RProp MLP Learner
- Nodes / Analytics / Mining / Neural Network / MLP / MultiLayerPerceptron Predictor
- Nodes / IO / Write / PMML Writer
精度比較
各モデルの精度を比較するため、Bar Chartを作成します。1. MLP (Multi Layer Perceptron) が最も良く、続いて 2. Random Forest (ランダムフォレスト)、3. Logistic Regression (ロジスティック回帰) と 4. Decision Tree (決定木) は同値という結果です。
Legend説明
- MLP: Multi Layer Perceptron
- RF: Random Forest
- LR: Logistic Regression
- DT: Decision Tree
Fig. 精度比較 / Bar Chart
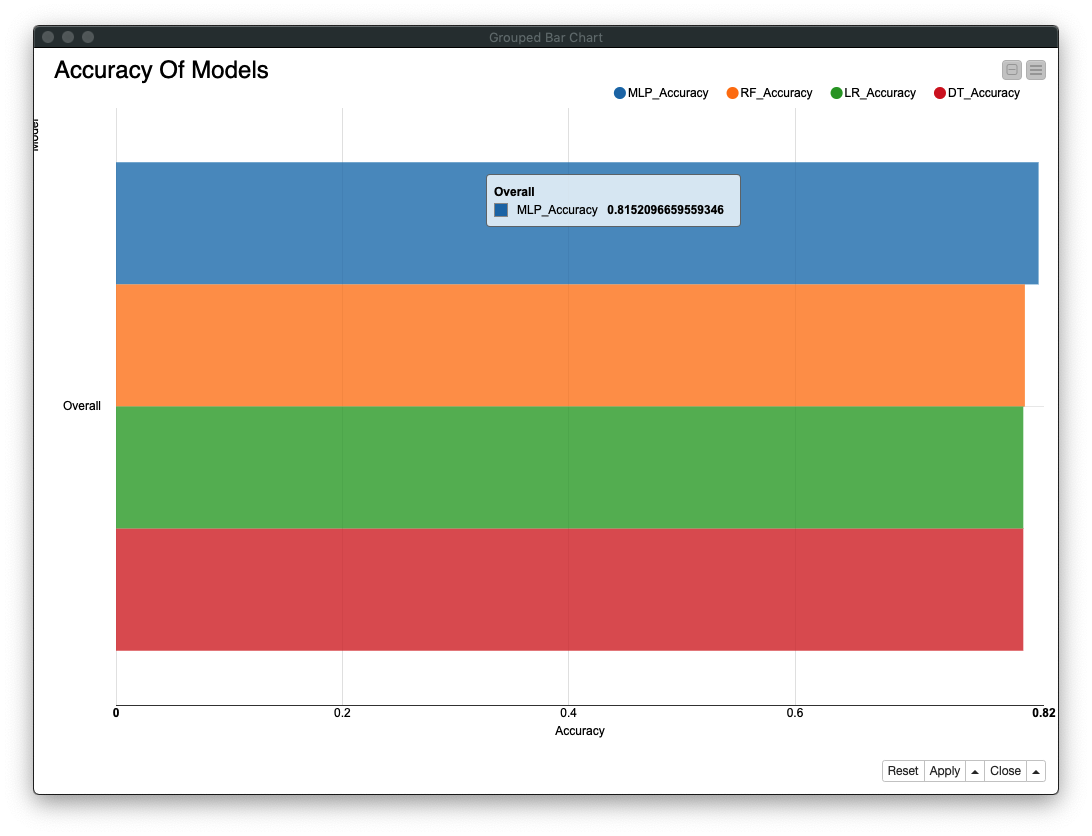
Fig. 精度比較 / ROC Curve (ROC曲線)
ROC曲線で比較すると、1. MLP (Multi Layer Perceptron) が最も良く、続いて 2. Logistic Regression (ロジスティック回帰)、3. Random Forest (ランダムフォレスト)、4. Decision Tree (決定木) という結果です。
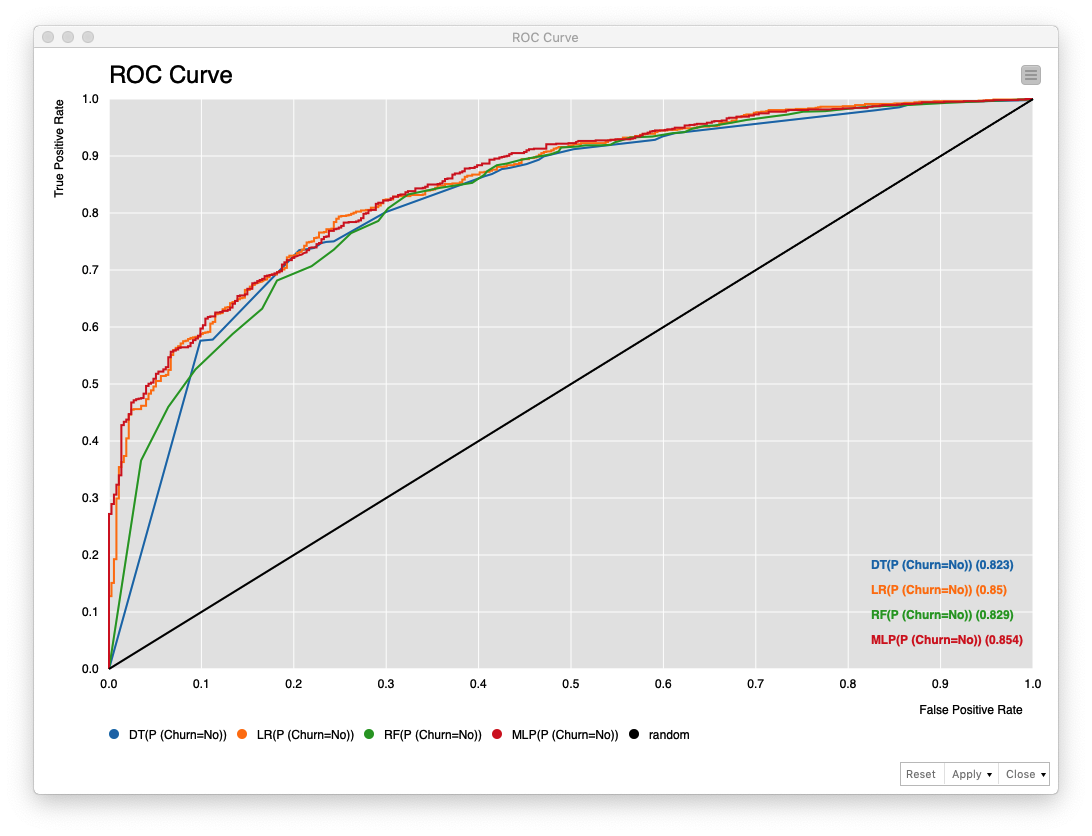
以上の評価結果を総合すると、今回のケースでは、MLP (Multi Layer Perceptron) を選択した方が良いということになります。
利用ノード一覧
前処理
- IO / Read / CSV Reader
- Nodes / KNIME Labs / JavaScript Views (Labs) / Data Explorer
- Nodes / Views / Property / Color Manager
- Nodes / Manipulation / Row / Filter / Row Filter
- Nodes / Manipulation / Column / Convert & Replace
- Nodes / Manipulation / Row / Transform / Partitioning
モデル作成 + モデル評価
- Nodes / Analytics / Mining / Decision Tree / Decision Tree Learner
- Nodes / Analytics / Mining / Decision Tree / Decision Tree Predictor
- Nodes / Views / JavaScript / Decision Tree View
- Nodes / Analytics / Mining / Logistic Regression / Logistic Regression Learner
- Nodes / Analytics / Mining / Logistic Regression / Logistic Regression Predictor
- Nodes / Analytics / Mining / Decision Tree Ensemble / Random Forest / Classification / Random Forest Learner
- Nodes / Analytics / Mining / Decision Tree Ensemble / Random Forest / Classification / Random Forest Predictor
- Nodes / Analytics / Mining / Neural Network / MLP / RProp MLP Learner
- Nodes / Analytics / Mining / Neural Network / MLP / MultiLayerPerceptron Predictor